
You probably have notice that the public debate has been recently dominated by security issues – at least, it has been the case in France. The attacks in Paris on November 13, 2015 participated in putting this subject as one of the most debated. Yet, if the need to take some measures, probably real, is often stressed out, my impression, indeed not supported by a comprehensive study, is that the question of the effectiveness of these measures generally do not arise. However, even if it takes a bit to have the necessary perspective to assess the question of effectiveness, it is generally possible to carry out an a priori study.
Let take as an example the law on intelligence, promulgated in France on July 24, 2015 and which I have assess repeatedly, with a vue from here. Though we have to wait to judge its proven effects, a first assessment can been done using some simple statistics. This article was inspired by another one, published in the journal La Recherche in November 20151Claude Castelluccia and Daniel Le Métayer, 2015. Les failles de la loi sur le renseignement, La Recherche n° 505, pp. 61 – 65.. Our conclusions are compatible.
Edward Snowden’s revelations have prompted the National Security Agency to unconditionally defend the global surveillance program as implemented in the United States since the attacks of September 11, 2001. However, we now know that internally the effectiveness of the program was seriously questioned (the link lead to a French-speaking website). Yet others, such as France and some Canadian provinces want to adopt similar programs.
However, simple statistics already can be used to produce a first assessment of what can be expected of such a law. I intend to do so in this article, but first, we must set some vocabulary.
We will use some statistical test to determine whether a given individual meets a characteristic – in this case, we want to know if it is a jihadist. If the test indicates the individual has this feature and it is actually the case (the individual has been identified as jihadist and it is indeed a jihadist), we speak of true positive. If the individual is identified as not having the characteristic and that is indeed the case (the individual is identified as not being jihadist and this is the case), it is called true negative. When the individual is identified as not having the characteristic while he/she has it (the individual was considered as not being jihadist, but he/she is one), it is called false negative. Finally, if the individual is considered as having the characteristic when it is not the case (the individual has been identified as jihadist while he/she is not), it is called false positive.
I hope the above paragraph was not too indigestible, but it is good to use the appropriate vocabulary.
According to French administration (the link leads to a French-speaking website, but there are mainly numbers in it), the French population in 2016 amounted to 66.628 million people (the number is provisional at the time I am writing this article). As the entire French population does not use the Internet, let consider that there are about 50 million Internet users in France (the link leads to a French-speaking website). Furthermore, in January 2015 (the link leads to a French-speaking website), the French Prime Minister Manuel Valls said that 3000 people were monitored for potential radicalisation, including 1300 potential jihadists. In the following, I will assume that there are 5000 individuals who could potentially switch to jihadism. This most likely involves a substantial overestimation.
So it was decided to develop an algorithm to identify jihadists among French Internet users. Suppose that the algorithm is exceptional, so its real positive rate is 99 % while its false positive rate is 0.5 % – in fact, it is very unlikely that the algorithm, even extremely well done, will reach such flattering statistics. This algorithm therefore correctly detect 5000 × 0.99 = 4950 terrorists, thus causing 50 false negatives. However, it is the cause of (50,000,000 − 5000) × (0.5 / 100) = 249,975 false positive. In other words, an individual identified as a jihadist by such a system would have a probability of about 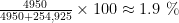
So there are real indications that in such a system false positives are the rule and true positives are the exception. This, knowing that before the adoption of the law on intelligence, all the terrorists who struck France had been the subject of an information sheet (the link leads to a French-speaking website). The difficulties experienced by the services were therefore not in the detection of potentially dangerous individuals, but in what comes next. In this context, greatly increase the number of files, literally drowning the cases that are truly to be treated, may increase all the difficulties. For instance, a police officer declared to French newspaper Le Monde in december 2015 (the link leads to a French-speaking website) that “the services sends files as they are thrown in the trash,” which is in line with an over-abundance of records. What also worries is that some politicians propose to detain any person being the subject of an information sheet (the link leads to a French-speaking website).
We opted for the law on intelligence. So be it. However, it is important to provide the means to assess what have been the effects and consequences of this law. More generally, ethical questioning of any measure that one is about to adopt is relevant and necessary. However, this example seems to me to show that it is equally important to consider what we can anticipate concerning its efficiency and its consequences. I regret that we do not make the effort of this assessment more often.
Notes
| ↑1 | Claude Castelluccia and Daniel Le Métayer, 2015. Les failles de la loi sur le renseignement, La Recherche n° 505, pp. 61 – 65. |
|---|
One thought on “Statistical analysis of the law on intelligence”